Mitigating the Burden of Redundant Datasets via Batch-Wise Unique Samples and Frequency-Aware Losses
Abstract
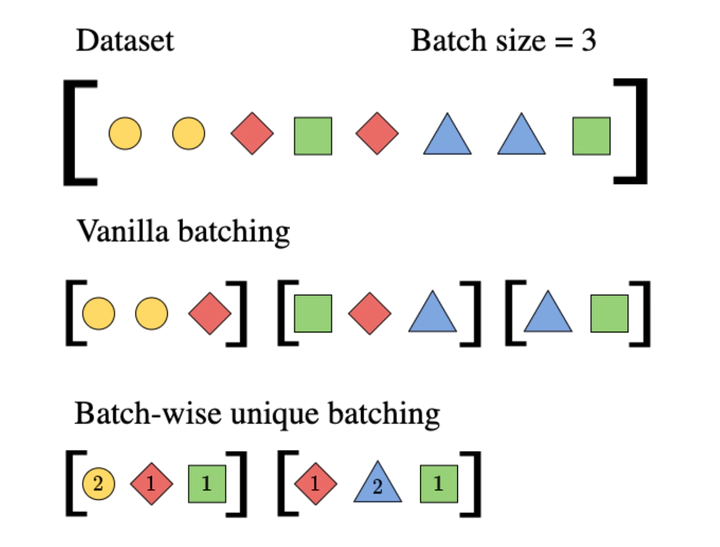
Datasets used to train deep learning models in industrial settings often exhibit skewed distributions with some samples repeated a large number of times.This paper presents a simple yet effective solution to reduce the increased burden of repeated computation on redundant datasets.Our approach eliminates duplicates at the batch level, without altering the data distribution observed by the model, making it model-agnostic and easy to implement as a plug-and-play module. We also provide a mathematical expression to estimate the reduction in training time that our approach provides. Through empirical evidence, we show that our approach significantly reduces training times on various models across datasets with varying redundancy factors, without impacting their performance on the Named Entity Recognition task, both on publicly available datasets and in real industrial settings.In the latter, the approach speeds training by up to 87{%}, and by 46{%} on average, with a drop in model performance of 0.2{%} relative at worst.We finally release a modular and reusable codebase to further advance research in this area..
Donato Crisostomi
Incoming AI Safety Fellow @ Anthropic
My research interests revolve around artificial intelligence, in particular model merging and representational alignment.