Abstract
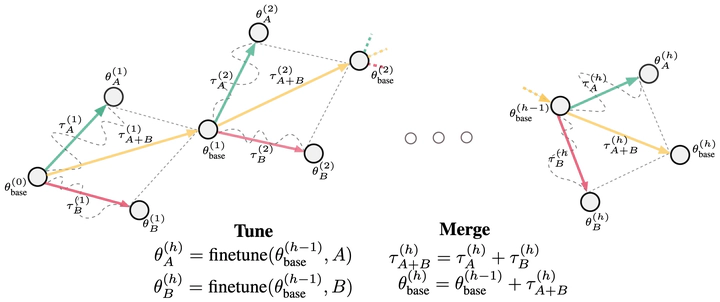
Model merging has recently emerged as a cost-efficient paradigm for multi-task learning. Among current approaches, task arithmetic stands out for its simplicity and effectiveness. In this paper, we motivate the effectiveness of task vectors by linking them to multi-task gradients. We show that in a single-epoch scenario, task vectors are mathematically equivalent to the gradients obtained via gradient descent in a multi-task setting, and still approximate these gradients in subsequent epochs. Furthermore, we show that task vectors perform optimally when equality is maintained, and their effectiveness is largely driven by the first epoch’s gradient. Building on this insight, we propose viewing model merging as a single step in an iterative process that Alternates between Tuning and Merging (ATM). This method acts as a bridge between model merging and multi-task gradient descent, achieving state-of-the-art results with the same data and computational requirements. We extensively evaluate ATM across diverse settings, achieving up to 20% higher accuracy in computer vision and NLP tasks, compared to the best baselines. Finally, we provide both empirical and theoretical support for its effectiveness, demonstrating increased orthogonality between task vectors and proving that ATM minimizes an upper bound on the loss obtained by jointly finetuning all tasks.
Donato Crisostomi
ELLIS Ph.D. Student @ Sapienza/Cambridge
My research interests revolve around artificial intelligence, in particular model merging and representational alignment.